If you’ve ever felt confused by AI terminology—wondering what an LLM is, how ChatGPT actually works, or why there seem to be 500 different AI tools that all do the same thing—this guide is for you.
I wrote this because I was confused too. The AI space moves fast, the jargon is thick, and most explanations assume you already know half the terminology. So here’s my attempt at making sense of it all, starting from the basics and building up to the stuff that actually matters for using AI in the real world.
What’s in This Guide
- The Big Picture—What Is AI, Really?
- The Hierarchy—AI, Machine Learning, Deep Learning, and LLMs
- Machine Learning Explained
- Neural Networks and Deep Learning
- Large Language Models (LLMs)—The ChatGPT Engine
- How AI Models Are Trained
- The Technical Stuff You’ll Hear About
- APIs, Wrappers, and Why There Are 500 “ChatGPT Alternatives”
- Local vs. Cloud AI
- What AI Can and Can’t Do (Honest Assessment)
Section 1: The Big Picture—What Is AI, Really?
Let’s start with the most basic question: what actually is artificial intelligence?
At its core, AI is software that can perform tasks that typically require human intelligence. That’s it. No magic, no sentience, no robot apocalypse. Just software doing clever things with data.
These “clever things” include recognizing images, understanding and generating language, making predictions, playing games, and yes, having conversations that feel surprisingly human. But here’s what AI is NOT:
AI is not conscious or sentient. ChatGPT doesn’t “think” or “feel” anything. It’s predicting what text should come next based on patterns. Very sophisticated pattern-matching, but pattern-matching nonetheless.
AI is not a single thing. “AI” is an umbrella term covering many different technologies, approaches, and capabilities. Saying you “work in AI” is like saying you “work in software”—technically true but not very specific.
AI is not magic. Every AI system has specific training, specific capabilities, and specific limitations. The impressive demos you see online don’t represent typical daily performance.
Section 2: The Hierarchy—AI, Machine Learning, Deep Learning, and LLMs
Here’s where most explanations lose people. These terms get thrown around interchangeably, but they’re actually nested categories—like Russian dolls of increasing specificity.
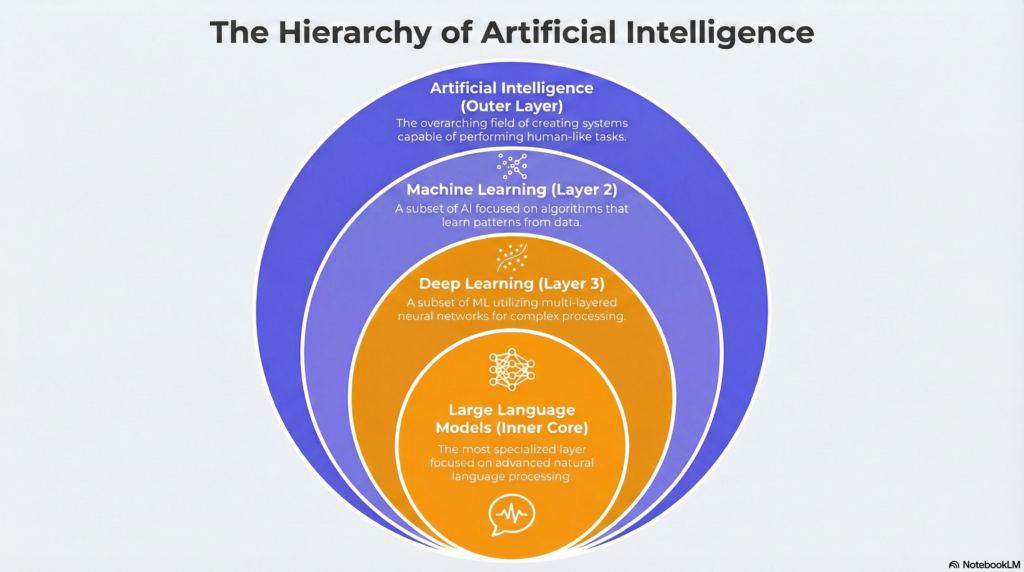
Artificial Intelligence (the biggest circle): Any software that mimics human cognitive abilities. This includes everything from simple rule-based systems (“if customer says X, respond with Y”) to sophisticated neural networks. AI has existed as a concept since the 1950s.
Machine Learning (inside AI): A subset of AI where systems learn from data rather than following explicit rules. Instead of programming every decision, you show the system examples and it figures out the patterns. ML became practically useful in the 1990s-2000s.
Deep Learning (inside ML): A subset of machine learning using neural networks with many layers. “Deep” refers to the depth of these layers. Deep learning enabled major breakthroughs starting around 2012, especially in image and speech recognition.
Large Language Models/LLMs (inside Deep Learning): A specific type of deep learning model trained on massive amounts of text to understand and generate language. ChatGPT, Claude, Gemini, and Llama are all LLMs. This is the technology behind the current AI boom.
So when someone asks “what’s the difference between AI and machine learning?”—machine learning is a type of AI. And when they ask about ChatGPT—that’s an LLM, which is a type of deep learning, which is a type of machine learning, which is a type of AI.
Section 3: Machine Learning Explained
Traditional programming works like this: you write explicit rules, and the computer follows them. If this, then that. It’s like giving someone a detailed instruction manual.
Machine learning flips this. Instead of writing rules, you show the computer examples and it figures out the rules itself. It’s like teaching a child to recognize dogs—you don’t explain the exact pixel patterns that constitute a dog, you just show them lots of dogs until they get it.
There are three main types of machine learning:
Supervised Learning
Learning from labeled examples. You give the system inputs paired with correct outputs (“this email is spam,” “this image is a cat”), and it learns to make those classifications for new data. Most AI you interact with uses supervised learning somewhere in its training.
Example: Show an AI 10,000 photos labeled “cat” or “dog,” and it learns to classify new photos it’s never seen.
Unsupervised Learning
Learning patterns without labels. The system finds structure in data on its own—grouping similar items, detecting anomalies, discovering hidden patterns. Less common in consumer AI but important for research and data analysis.
Example: An AI analyzes customer purchase data and discovers natural groupings you never defined (budget shoppers, premium seekers, impulse buyers).
Reinforcement Learning
Learning through trial and error with rewards. The AI tries actions and receives positive or negative feedback, gradually learning which actions lead to good outcomes. This is how game-playing AIs and some robotics systems learn.
Example: An AI learns to play chess by playing millions of games against itself, getting rewarded for wins and penalized for losses until it becomes superhuman.
Section 4: Neural Networks and Deep Learning
You’ve probably heard that neural networks are “inspired by the brain.” This is technically true but also kind of misleading. They’re inspired by a simplified, mathematical model of how neurons might work—not a realistic simulation of brain biology.
Here’s the basic idea: a neural network is made up of layers of connected “nodes” (artificial neurons). Data flows through these layers, with each layer transforming the data in some way.
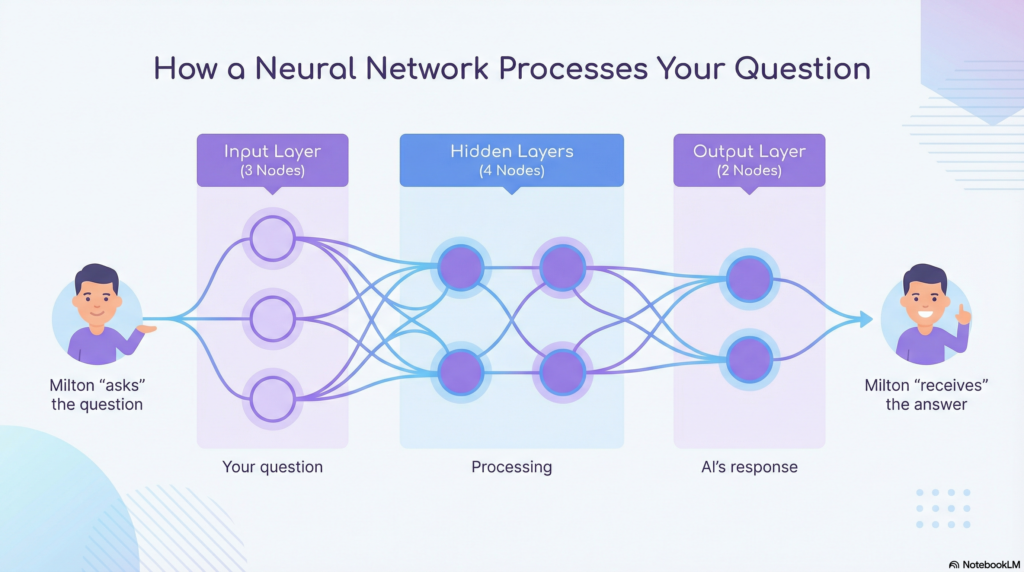
Input Layer: Where data enters the network. For image recognition, this might be the pixel values of an image. For language, it’s numerical representations of words.
Hidden Layers: The layers in between that do the actual “thinking.” Each layer extracts increasingly abstract patterns. Early layers might detect edges in an image; later layers might recognize faces.
Output Layer: Where the result comes out. This could be a classification (“cat” or “dog”), a prediction (“80% likely to rain”), or generated content (the next word in a sentence).
“Deep” learning just means using neural networks with many layers—sometimes hundreds or thousands. More layers allow the network to learn more complex patterns, but they also require much more data and computing power to train.
The breakthrough that enabled modern deep learning wasn’t a new algorithm—it was hardware. GPUs (graphics processing units), originally designed for video games, turned out to be perfect for the parallel calculations neural networks need. Without cheap, powerful GPUs, we wouldn’t have ChatGPT.
Section 5: Large Language Models (LLMs)—The ChatGPT Engine
Now we get to the technology that’s actually causing all the excitement. Large Language Models are a specific type of deep learning model designed to understand and generate human language.
Here’s the core insight that makes LLMs work: at their heart, they’re prediction machines trained on an absurdly simple task—predict the next word.
That’s it. Take a sequence of words, predict what word comes next. Do this training on trillions of words from the internet, books, articles, and code. Scale it up with billions of parameters and massive computing power. And somehow, out of this simple next-word prediction task, emergent capabilities appear—the model learns to write essays, answer questions, write code, and have conversations.
How does predicting the next word lead to apparent intelligence? Consider this: to accurately predict what word comes next in “The capital of France is ___,” you need to have encoded knowledge about geography. To predict the next word in a math problem, you need something like mathematical reasoning. By training on virtually all text ever written, LLMs absorb patterns that look remarkably like knowledge and reasoning.
The “Transformer” Architecture
In 2017, researchers at Google published a paper titled “Attention Is All You Need” that introduced the transformer architecture. This became the foundation for essentially all modern LLMs.
The key innovation was the “attention mechanism”—a way for the model to consider relationships between all parts of the input simultaneously, rather than processing it word by word in sequence. This allows transformers to understand context much better than previous approaches.
When you see model names like GPT (Generative Pre-trained Transformer), BERT, or LLaMA—the “T” or the underlying architecture is transformers.
Why LLMs “Hallucinate”
Remember: LLMs are predicting plausible text, not retrieving verified facts. They don’t have a database of true statements they look things up in. They generate text that statistically resembles their training data.
This means they can confidently produce completely false information—what we call “hallucinations.” Ask for a citation and the model might invent a realistic-looking paper that doesn’t exist. Ask about a recent event beyond its training data and it might fabricate details.
This isn’t a bug that will be easily fixed. It’s inherent to how these systems work. They’re not looking up answers; they’re generating probable text based on patterns. Sometimes those patterns produce truth. Sometimes they produce convincing fiction.
Section 6: How AI Models Are Trained
Training a large language model is a massive undertaking that costs millions of dollars and requires enormous computing resources. Here’s how it works:
Step 1: Data Collection
First, you need data. Lots of it. Modern LLMs are trained on datasets containing trillions of tokens (word-pieces) scraped from the internet, books, academic papers, code repositories, and other sources. This data represents a substantial fraction of publicly available text.
The quality and composition of training data matters enormously. If your training data contains errors, biases, or toxic content, the model learns those too. Data curation is one of the most important (and expensive) parts of training.
Step 2: Pre-training
The model is trained on that massive dataset using the next-word prediction task. This phase requires thousands of specialized GPUs running for weeks or months. This is where most of the computational cost goes.
After pre-training, you have a “base model” that’s good at predicting text but not particularly good at following instructions or having helpful conversations. It might continue your prompt with any plausible text—not necessarily a useful answer.
Step 3: Fine-tuning
The base model is then fine-tuned on more specific data for the intended use case. For a chatbot, this means training on examples of helpful conversations. For a coding assistant, examples of code explanations. Fine-tuning is cheaper and faster than pre-training but still significant.
Step 4: RLHF (Reinforcement Learning from Human Feedback)
This is the secret sauce that makes models like ChatGPT and Claude actually useful. Human evaluators rate AI responses, and those ratings train the model to produce outputs humans prefer. RLHF teaches the model to be helpful, follow instructions, avoid harmful content, and admit uncertainty.
Without RLHF, base models are impressive but often frustrating—they might answer questions with more questions, produce inappropriate content, or go wildly off-topic. RLHF shapes the raw capability into something useful.
Parameters: The Model’s “Brain Size”
You’ll often hear about models having billions of “parameters.” Parameters are the adjustable values in the neural network—the knobs that get tuned during training. More parameters generally means more capability, but also higher costs to train and run.
For reference: GPT-3 had 175 billion parameters. GPT-4’s exact size isn’t public but is rumored to be over a trillion. Smaller open-source models like Llama range from 7 billion to 70 billion parameters.
Section 7: The Technical Stuff You’ll Hear About
Here are the terms you’ll encounter when using AI tools, explained practically:
Tokens: AI doesn’t process text as words—it breaks text into “tokens,” which are roughly word-parts. “Hello” is one token, but “unconstitutional” might be four tokens. Token counts matter because they determine both cost (you pay per token) and context limits (the model can only process so many tokens at once). A rough rule: 1 token ≈ 4 characters or ¾ of a word.
Context Window: The maximum amount of text the model can consider at once—both your input and its response. Think of it as short-term memory. GPT-3.5 has about 4,000 tokens (≈3,000 words). GPT-4 offers up to 128,000 tokens. Claude offers up to 200,000 tokens. Larger context windows let you include more information but cost more.
Temperature: A setting that controls randomness in the AI’s responses. Low temperature (0-0.3) makes responses more predictable and consistent—good for factual tasks. High temperature (0.7-1.0) makes responses more varied and creative—good for brainstorming. Think of it as a “creativity dial.”
Prompts: The input you give to the AI. This includes your question or instruction, but can also include context, examples, or specific formatting requirements. How you phrase your prompt significantly affects the output quality—hence “prompt engineering.”
System Prompts: Special instructions given to the AI that set its behavior for the entire conversation. These often define the AI’s persona, rules, and default behaviors. When you use ChatGPT, there’s a system prompt you don’t see that tells it how to behave.
Section 8: APIs, Wrappers, and Why There Are 500 “ChatGPT Alternatives”
This is where a lot of confusion comes from. Let me clear it up.
An API (Application Programming Interface) is a way for software to communicate with other software. OpenAI, Anthropic, Google, and others offer APIs that let developers send text to their models and receive responses. You send a request, you get back AI-generated text.
This means anyone can build an app that uses GPT-4 or Claude under the hood without training their own model. They just pay per API call.
A “wrapper” is an application built on top of these APIs. Many of the “AI writing tools” and “ChatGPT alternatives” you see are wrappers—they provide a different interface, specialized prompts, or additional features, but the core AI is coming from OpenAI or Anthropic’s API.
This isn’t inherently bad. A well-designed wrapper can genuinely add value through better UX, specialized templates, or integrations with other tools. But it’s worth understanding that “500 AI writing tools” might really be “500 different interfaces to the same 3 underlying models.”
The Major Players
Here are the companies actually building foundation models:
OpenAI: Created GPT-4, ChatGPT, and DALL-E. Currently the most well-known, with the largest market share. Closed-source models only available via their API or ChatGPT interface.
Anthropic: Created Claude. Founded by former OpenAI researchers with a focus on AI safety. Known for long context windows and nuanced, thoughtful responses. Also closed-source.
Google: Created Gemini (formerly Bard). Integrated into Google products. Has massive resources and data but entered the chatbot race later than OpenAI.
Meta: Created Llama, which they released as open source. This lets researchers and companies run and modify the model themselves. Llama has spawned a huge ecosystem of fine-tuned variants.
Mistral: A French company making efficient open-source models that rival much larger models in performance. Known for good performance per parameter.
Section 9: Local vs. Cloud AI
When you use ChatGPT or Claude, your requests go to servers owned by OpenAI or Anthropic. That’s “cloud AI.” But it’s also possible to run AI models directly on your own computer—”local AI.”
Cloud AI Pros:
- Most powerful models available (GPT-4, Claude) are cloud-only
- No hardware requirements—works on any device with internet
- Always up-to-date
- Handles complex, long requests without your computer breaking a sweat
Cloud AI Cons:
- Privacy concerns—your data goes to third-party servers
- Ongoing costs (pay per use or subscription)
- Requires internet connection
- Subject to usage limits and rate limiting
Local AI Pros:
- Complete privacy—data never leaves your device
- No ongoing costs after initial setup
- Works offline
- Full control and customization
Local AI Cons:
- Requires capable hardware (good GPU with significant VRAM)
- Best models (GPT-4, Claude) aren’t available locally
- More technical setup required
- Slower on consumer hardware
For most people, cloud AI makes more sense—it’s easier, more powerful, and the privacy tradeoffs are acceptable for most tasks. Local AI is worth exploring if you have specific privacy requirements, work offline frequently, or just enjoy tinkering.
Tools like Ollama and LM Studio make local AI more accessible, letting you run models like Llama with a few clicks rather than complex command-line setup.
Section 10: What AI Can and Can’t Do (Honest Assessment)
Let me give you an honest assessment of current AI capabilities, without the hype or doom:
What AI Does Well Today:
Writing assistance: Drafting emails, editing prose, overcoming blank-page paralysis, adjusting tone, summarizing documents. AI is genuinely useful here.
Coding help: Explaining code, suggesting implementations, debugging, writing boilerplate, converting between languages. Professional developers use it daily.
Research and explanation: Explaining complex topics at any level, providing overviews of unfamiliar subjects, answering questions. Great starting point, though verify important facts.
Analysis and synthesis: Comparing options, identifying patterns in text, summarizing long documents, extracting key points.
Translation: Between languages, between technical and plain language, between formats.
Brainstorming: Generating ideas, alternatives, and possibilities you might not have considered.
What AI Struggles With:
Factual accuracy: AI can and does make things up while sounding completely confident. Never trust AI for critical facts without verification.
Mathematics: Despite apparent reasoning abilities, LLMs frequently make arithmetic errors and can’t reliably do complex math. They’re getting better but aren’t trustworthy for calculations.
Real-time information: Models have knowledge cutoff dates. They don’t know about events after their training data ended unless they have web access features.
Consistent reasoning: AI can fail on simple logic puzzles while succeeding at complex ones. Its reasoning is pattern-matching, not actual logic, so it’s inconsistent.
Anything requiring physical world interaction: AI can’t actually do anything in the physical world without being connected to other systems.
The Gap Between Demos and Daily Use
Be aware that impressive demos often represent cherry-picked best cases, carefully crafted prompts, and edited outputs. Daily use is messier. AI is incredibly useful as a tool but requires human judgment, oversight, and editing. Think of it as a very capable but sometimes unreliable assistant, not a replacement for human expertise.
Where to Go From Here
You now understand the fundamentals of how AI actually works. Not everything, but enough to have informed conversations, evaluate tools, and use AI more effectively.
Next steps:
For quick definitions: Check the AI Glossary for any terms that are still fuzzy.
For historical context: Read AI History to understand how we got here and where things might go.
For practical application: Browse our tool comparisons and how-to guides (coming soon).